
Toegankelijk gaat niet meer over het web, kapotte ogen, gebroken armen en dove mensen. Het gaat over robot’s in staat te stellen het juiste antwoord te geven, informatie makkelijk te mixen en relateren aan elkaar. Daarom is het tijd voor de een nieuwe manier van content MAKEN, een gericht op BETERE informatie
Ik zag zojuist onderstaande fantastische plaat met mannetjes en vrouwtjes met diverse beperkingen. Het leuke is dat de beperkingen niet alleen gebreken zijn, zoals een gebroken arm, maar ook situaties zoals een kind in je arm. Netto levert het hetzelfde op: je kan op dat moment niets met je arm. Dus wat doet het web om dan alsnog lekker aan de slag te kunnen?
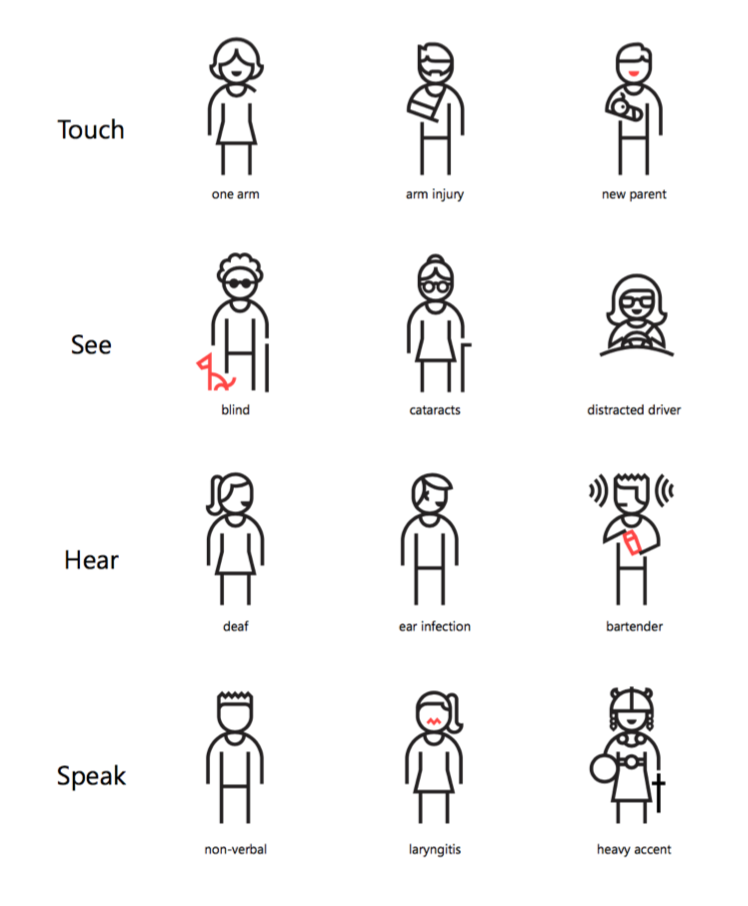
Dit stuk gaat niet over WAIARI, WCAG, maar over nieuwe interfaces.
Wat we af en toe vergeten is dat we op zo veel verschillende manieren informatie tot ons nemen en ook super snel communiceren met elkaar en met bedrijven, dat het vastpinnen van al die content en toegankelijkheid op het web eigenlijk te weinig en altijd te laat is.
Al die content- en vormgevingstips en technische aanwijzingen voor toegankelijkheid zijn prachtig voor het web, maar het is -in het kort- niet genoeg. We moeten de informatie namelijk nòg toegankelijker maken. Zó toegankelijk dat willekeurige interfaces er chocolade van kunnen maken en optimaal kunnen presenteren.
En met die interfaces bedoel ik bijvoorbeeld, maar niet gelimiteerd tot: sprekende interfaces zoals Amazon Echo en Siri, interfaces voor computerprogramma’s zoals een API, maar natuurlijk ook alle grote en piepkleine, lineaire en parallelle informatie schermweergaven. Nog belangrijker: ik heb het over de programma’s die onze vraag verbinden met het antwoord: de robots.

De robots helpen ons nog niet ècht, maar helpen wij de robots wel genoeg?
Websites zijn super onlogische manieren van informatie bieden. Ze leunen ondanks de semantische HTML initiatieven nog veel te veel op intentie van gebruik (volgorde, belangrijkheid, te investeren tijd, vorige en volgende actie).
Als je met een concrete vraag komt bij zo’n website ben je aangewezen dat de betreffende redacteur dat belangrijk genoeg vond èn ook nog dezelfde woorden gebruikt èn dat het vindbaar is gemaakt. Daarbij maken we onvoldoende gebruik van al het handigs in de HTML standaarden, zoals sections, links en microformats voor contactgegevens.
Misschien komen we een beetje in de buurt van leesbare tekst, maar het web zoals we dat nu kennen is voor robots meestal een onbruikbare hoop gebrabbel en in een optimaal geval een statisch relevant hoopje bytes.
Bruikbare informatie voor robots en daarmee ook mensen
Data en content word pas informatie zodra je het toepasbaar en relevant maakt en dat is nu voor het web en ogen van mensen redelijk te doen, want die zijn gemaakt om snel patronen te herkennen. Maar het is eigenlijk ondanks het web en dankzij alle handige tooltjes zoals Google gelukt.
Al die tooltjes zijn eigenlijk een foefje om je misschien een antwoord te geven, maar is dat ook het antwoord wat je zoekt? Is een volledige pagina waar jouw antwoord toevallig op staat hetgeen wat je wilt?
Wij kunnen redelijke vragen stellen aan Google en die bepalen statistisch wat het meest waarschijnlijk is wat je zoekt. Wat je eigenlijk wilt is niet aan de informatieboom rammelen en kijken wat eruit valt, maar met hoge trefzekerheid WETEN wat jij wilt en WETEN dat dit de juiste informatie is.
Van ‘I feel lucky’ naar ‘Here you go’
Robots kunnen ook makkelijk onze natuurlijke vragen analyseren en veel robots weten ook wat we bedoelen, maar kunnen simpel weg geen goed antwoord geven als ze niet de juiste data hebben. Kijk bijvoorbeeld naar een vraag over “wie is het vriendje van Ieniemienie?”. Google kan daar geen antwoord op geven. Ondanks dat het een super makkelijke vraag is, kan Google alleen maar wat pagina’s ophoesten waar de woorden ‘vriendje’ en ‘Ieniemienie’ voorkomen.
Het ligt er niet aan dat Google niet weet dat Sesamstraat een ding is en dat Tommie een ding is, maar wel dat Google niet snapt dat ‘vriendje’, Ieniemienie en Tommie een relatie impliceert. Dat staat nergens in robot-taal.
Als we willen dat robots, zoals Siri, maar ook diensten als Google en Apps ons nuttige antwoorden geven, moeten we ze helpen.
Het kan wel!
Robots begrijpen heel goed semantiek, context en relaties. Als je die drie combineert, dan kunnen ze chocolade maken van de beschikbare informatie. Kijk bijvoorbeeld naar hoe Amazon elke spelling en variant van ‘kaartendek’ snapt en producten aanbied die daarbij horen, inclusief andere spelletjes.
Zo ook met Google Maps. Omdat je met locaties te maken heb en dat de informatie geschikt is om routes en overzichten te bieden, kan je heel makkelijk vragen om een route te krijgen van A naar B.
Het enige verschil is dat robots de vraag met het antwoord kunnen verbinden, omdat ze chocolade kunnen maken van de vraag èn de beschikbare informatie.
TL;DR, de content maken met de robot-auto complete
We moeten informatie dus niet alleen toegankelijk, maar ook interpreteerbaar aanbieden voor robots en daarmee ook voor mensen. Dat kunnen we doen met bijvoorbeeld een API, of een programmeer interface, of door informatie in de HTML te voorzien van een heleboel meta-informatie (Ieniemienie is een pop op sesamstraat en is vriendjes met Pino en Tommie), maar dat is eigenlijk beide een gepasseerd station.
Ik denk dat we het makkelijker en beter kunnen en moeten oplossen bij de bron en robot’s laten helpen bij het creëren van informatie. Ik denk aan een centrale tool die helpt met èn leert van hoe wij informatie creëren. Denk aan een ‘auto complete’ functie die steeds slimmer word en ook steeds beter begrijpt wat voor soort informatie je maakt. Zo ontstaat er automatisch een meta-web tussen alle informatie-items.
Tot slot, achterhaald?
Maar Peet, dit is toch allemaal super achterhaald? Dit kan toch al? Nou, nee. We lopen met de meeste van onze creatie gereedschappen nog te rommelen met wel of geen WYSIWYG, terwijl een mening over vormgeving van redacteuren al jaren lang een doorn is het oog is van iedereen die websites maakt. Het gooit namelijk semantisch roet in het eten. Bold, tabellen, italic etc zegt namelijk niets over de waarde van de tekst.
Dus: we moeten stoppen met rommelen en de volgende stap nemen: laten we een nieuw web maken, een web van informatie, in plaats van een web van data. Dat kan door nieuwe tools te gebruiken die ons helpen informatie op te breken in logische, bruikbare stukjes waar robots chocolade van kunnen maken, zodat ze ons geen webpagina’s oplezen, maar antwoord geven.